HyperGraphRAG 论文解析:基于超图知识结构的检索增强生成
论文针对问题以及主要贡献
现有问题
- 传统 RAG 框架依赖基于分块的检索机制,即文本被分成定长的若干段,再通过密集向量匹配(dense vector matching)进行检索。这种机制不能捕捉实体之间的复杂关系,因此对于知识的建模能力很差,检索效率也较低。这一缺陷在需要细粒度知识的应用场景中尤为明显。
- 现有的 GraghRAG 方法使用传统图结构对知识进行表示,提高了检索准确度。但是传统图结构受限于二元关系(binary relations),而现实世界中往往存在多个实体共享同一个普遍关系的情况。此时现有的 GraphRAG 框架必须将其分为若干个孤立的二元关系,从而导致信息丢失。
核心贡献
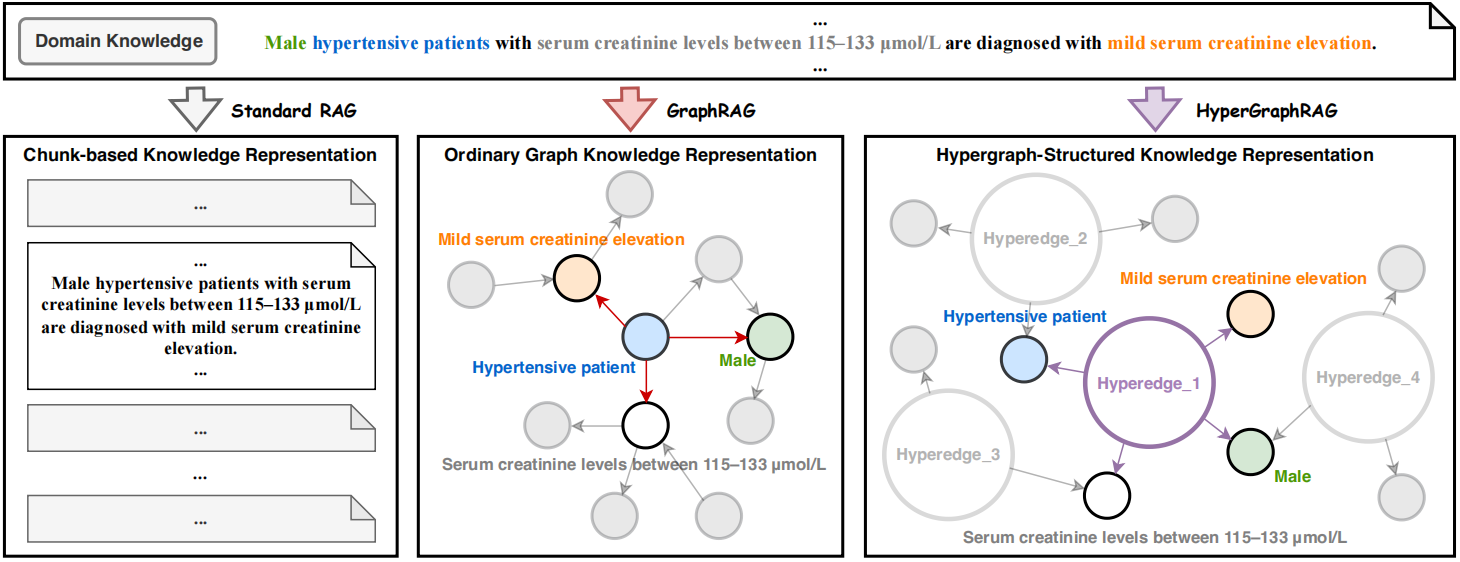
图 1:HyperGraphRAG 与其他 RAG 方法的比较
- 论文的核心贡献在于提出了一种基于超图(hypergraph)结构的知识表示方法:引入超边(hyperedges)来表示 n 元关系,从而增强知识表示能力,更适合知识推理操作。
- 论文的实现思路是:1、基于设计的提示词驱动大模型进行实体与多元关系提取,将生成的超图存储在二部图(bipartite graph)数据库中,并为节点和边分别建立向量数据库;2、设计检索机制用于检索相关实体以及超边;3、设计基于超边引导的生成机制,能够将检索到的多元事实与传统文本分段进行结合。
在图论中,二部图是一种图,其节点(顶点)可以被划分为两个不相交的集合 $U$ 和 $V$,并且每条边都连接一个 $U$ 中的节点和一个 $V$ 中的节点。也就是说:
- 同一集合内的节点之间没有边;
- 所有边都只在两个不同集合的节点之间。
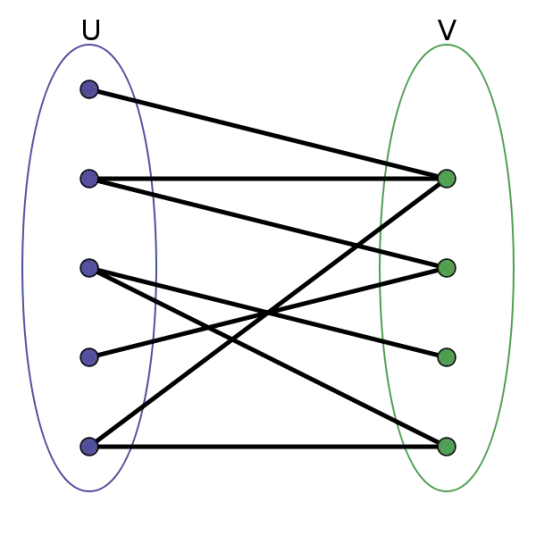
图 2:二部图
在图 1 中,可以把所有的超边移动到一侧,把所有的节点移到另一侧,这样结构就与二部图相同了。
公式化定义
$$ P(y | q) = \sum_{F \in G} P(y | q, F) P(F | q, G). $$
- $q$:表示输入的查询;
- $y$:表示生成的答案;
- $G = (V, E)$:表示知识图谱,$V$ 和 $E$ 分别表示节点和边的集合;其中 $G$ 由一系列事实 $F=(e, V_e) \in G$ 组成,其中 $e$ 代表关系,$V_e$ 是关系 $e$ 所连接的实体集合。
- $P(y | q, F)$:表示在给定查询 $q$ 和事实 $F$ 的条件下生成答案 $y$ 的概率;
- $P(F | q, G)$:表示在给定查询 $q$ 和知识图谱 $G$ 的条件下,选择关系 $F$ 的概率。
- $P(y | q)$:表示在给定查询 $q$ 的条件下,生成答案 $y$ 的概率。
该公式表达了在基于知识图谱 $G$ 的上下文中,回答查询 $q$ 所生成答案 $y$ 的概率建模方式。具体来说:
- 选择相关事实:首先根据查询 $q$ 和整个知识图谱 $G$,计算出一个分布 $P(F | q, G)$,即选择关系 $F$ 的概率。
- 基于事实生成答案:然后,在给定查询 $q$ 和某个特定事实 $F$ 的条件下,计算生成答案 $y$ 的概率 $P(y | q, F)$,也就是利用该事实进行局部推理并生成该答案的概率。
- 最终概率 $P(y | q)$ 是对所有可能的事实 $F$ 上的联合概率加权求和的结果。
上述公式定义了基于图的 RAG 广义概率模型。当图谱为超图时,有 $G_H = (V, E_H)$,其中 $E_H$ 是超边的集合;且有 $n$ 元关系 $F_n = (e_H, V_{e_H}) \in G_H$ 。这里的 $V_{e_H}$ 与 $F_n$ 中的 $V_e$ 不同,$V_{e_H}$ 是超边 $e_H$ 所连接的所有实体的集合,其数量可以超过 2 个,而 $V_e$ 只能是 2 个。
方法详述
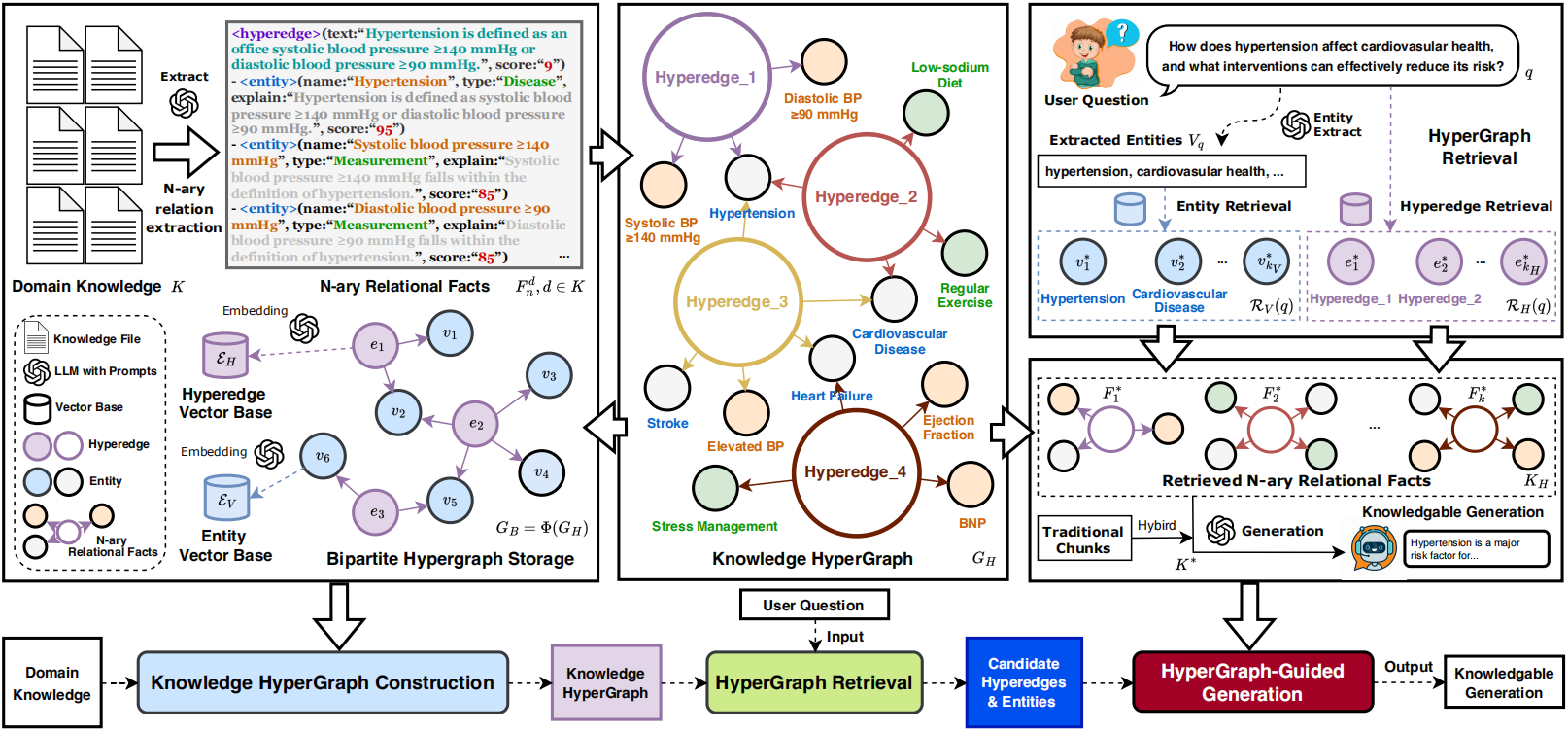
图 3:HyperGraphRAG 的方法框架
图谱构建
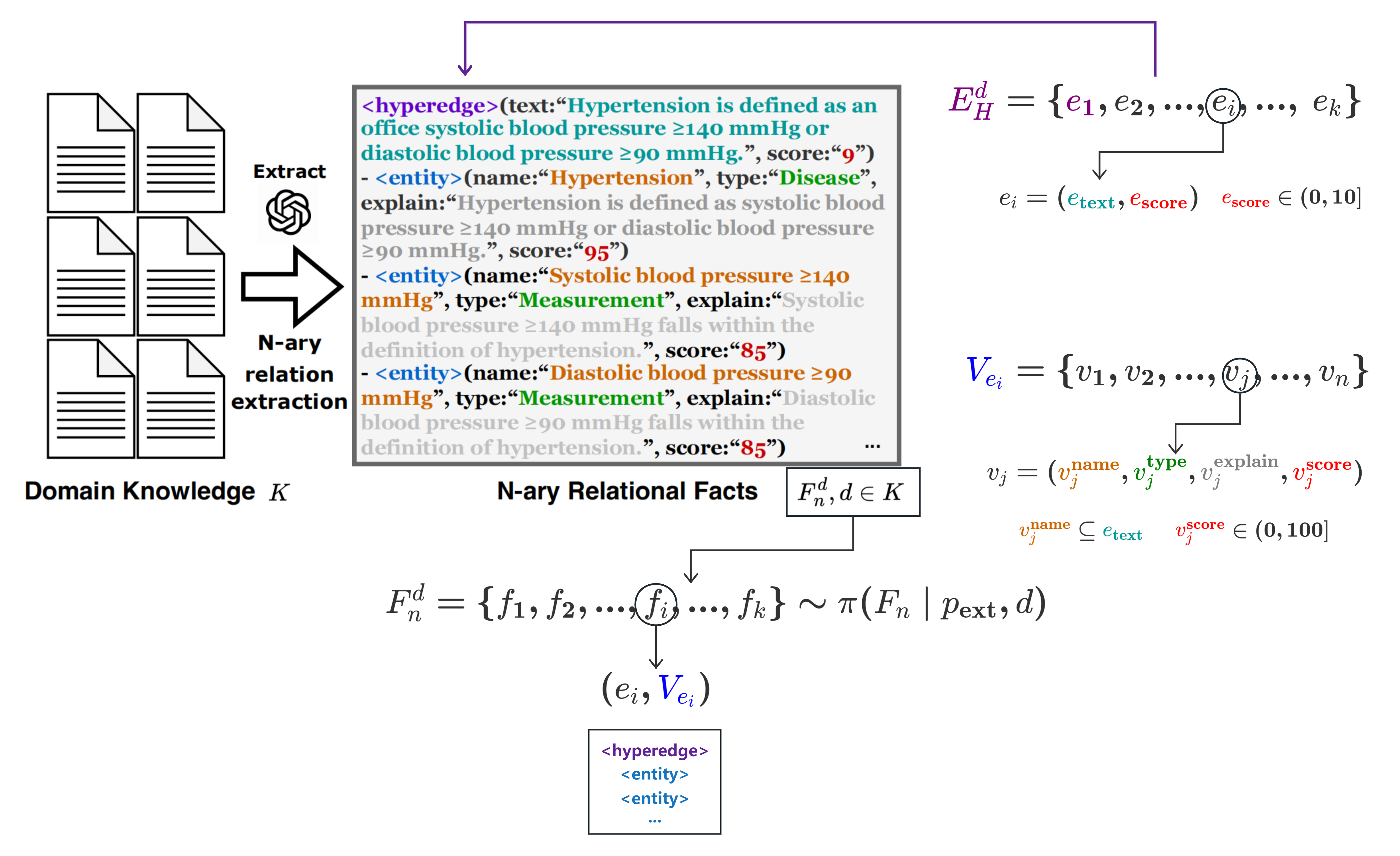
图 4:多元关系抽取
结合上图,我们可以理清论文的逻辑链路:
- 定义超边:$E_H^d = \{ e_1, e_2, …, e_k \}$,其中的任一元素 $e_i$ 对应上图中的紫色
<hyperedge>标签,分为text和score两部分; - 定义节点:$V_{e_i} = \{ v_1, v_2, …, v_n \}$,其中的任一元素 $v_j$ 对应上图中的蓝色
<entity>标签,分为name、type、explain和score四部分; - 提取事实: $$ F_n^d = \{ f_1, f_2, …, f_k \} \sim \pi(F_n | p_{\text{ext}}, d) $$ 给定文档 $d$ 和提示词 $p_{\text{ext}}$,使用大模型 $\pi$ 根据 $n$ 元关系模型 $F_n$ 抽取出多元关系 $F_n^d$。其中的任一元素 $f_i$ 都是一个超边 $e_i$,以及与其相连的实体集合 $V_{e_i}$ 的二元组,即 $(e_i, V_{e_i})$。
二部超图存储
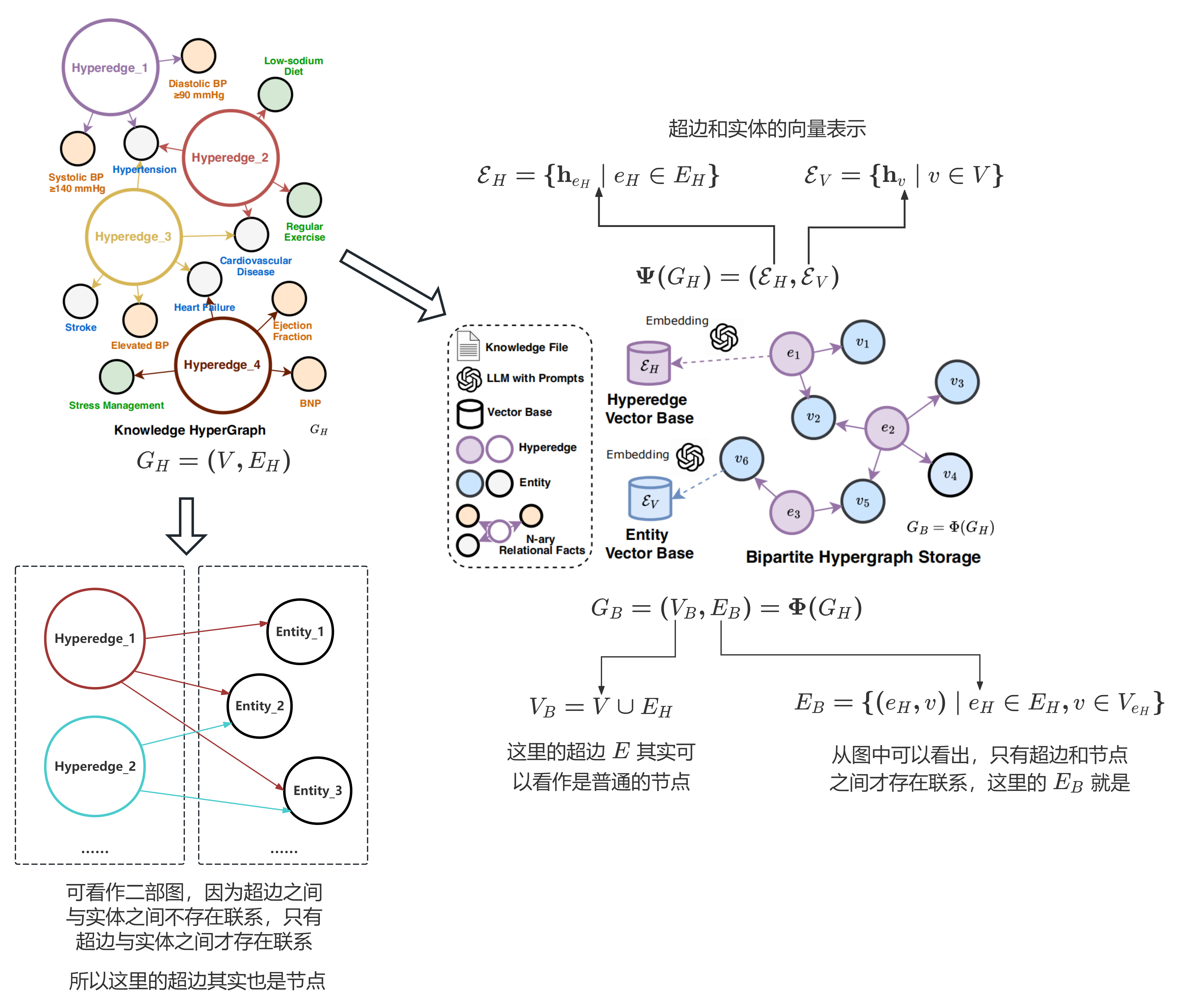
图 5:超边存储
从图中可以看出,论文中的超图无论是超边和节点,都可以当成传统图谱中的节点,只不过这个传统图谱是一个二部图,一侧的节点对应超边,另一侧是节点。论文所谓超边本质上是依借于二部图的性质存在的。
超图检索策略
实体抽取
$$ V_q \sim \pi(V \mid p_{\text{q\_ext}}, q) $$
给定用户查询 $q$ 和提示词 $p_{\mathrm{q\_ext}}$,使用大模型 $\pi$ 抽取出查询中的实体集合 $V_q$ 。
实体检索
在提取查询 $q$ 的实体后,需要从知识超图 $G_H$ 的实体集合 $V$ 中检索出最相关的实体。论文定义了实体检索函数 $\mathcal{R}_V$,该函数基于余弦相似度从 $\mathcal{E}_V$ 中检索出最相关的实体:
其中,$\mathbf{h}_{V_q} = f(V_q)$ 是所提取实体集合 $V_q$ 的拼接文本向量表示(concatenated text vector representation),$\mathbf{h}_v \in \mathcal{E}_V$ 是实体 $v$ 的向量表示(vector representation),$\text{sim}(\cdot, \cdot)$ 表示相似性函数(similarity function),$\odot$ 表示相似度与实体相关性得分 $v^{\text{score}}$ 之间的逐元素相乘(element-wise multiplication),用于确定最终的排序得分,$\tau_V$ 是实体检索得分的阈值(threshold),而 $k_V$ 是所检索实体数量的上限(limit)。
超边检索
此外,为了通过在知识超图 $G_H$ 的超边集 $E_H$ 中搜索完整的 $n$ 元关系来扩展检索范围,论文定义了超边检索函数 $\mathcal{R}_H$,用于检索与 $q$ 相关的一组超边:
超图指导的生成机制

图 6:生成机制
超图知识融合
如上图所示,从用户查询 $q$ 中提取出超边和实体后,使用提取出的超边在图数据库中匹配对应的实体,从而形成一个超边——实体集合;使用提取出的实体在图数据库中匹配对应的超边,从而形成一个实体——超边集合。这两个集合进行合并形成最终的 $n$ 元关系事实:
$$ K_H = \mathcal{F}_V^* \cup \mathcal{F}_H^* $$
增强生成
在完成超图知识融合之后,论文采用了一种混合的 RAG 融合机制,将超图知识 $K_H$ 与基于分块(chunk-based)检索得到的文本片段 $K_{\text{chunk}}$ 结合,形成最终的知识输入。
论文将最终的知识输入 $K^*$ 定义为:
$$ K^* = K_H \cup K_{\text{chunk}} $$
其中 $K_{\text{chunk}}$ 是通过传统 RAG 方法基于分块文档片段检索所得:
其中 $\mathbf{h}_q$ 表示查询 $q$ 的向量表示,$\mathbf{h}_d$ 表示基于分块的文档片段 $d$ 的向量表示,$\tau_C$ 是分块检索的相似度阈值,而 $k_C$ 则限制了检索所得分块的数量。
最后,论文使用一个增强检索的生成提示 $p_{\text{gen}}$,该提示结合了超图知识 $K^*$ 与用户问题 $q$,作为大语言模型 $\pi$ 的输入,以生成最终的答案:
$$ y^* \sim \pi(y|p_{\text{gen}},K^*,q), $$
其中 $y^*$ 是生成的响应。
附录
$n$ 元关系抽取提示词
-Goal- Given a text document that is potentially relevant to this activity and a list of entity types, identify
all entities of those types from the text and all relationships among the identified entities. Use {language} as output language. -Steps- 1. Divide the text into several complete knowledge segments. For each knowledge segment, extract the following information: -- knowledge_segment: A sentence that describes the context of the knowledge segment. -- completeness_score: A score from 0 to 10 indicating the completeness of the knowledge
segment. Format each knowledge segment as ("hyper-relation"{tuple_delimiter}<knowledge_segment>{tuple_delimiter}<completeness_score>)
2. Identify all entities in each knowledge segment. For each identified entity, extract the following
information: - entity_name: Name of the entity, use same language as input text. If English, capitalized the
name. - entity_type: Type of the entity. - entity_description: Comprehensive description of the entity's attributes and activities. - key_score: A score from 0 to 100 indicating the importance of the entity in the text. Format each entity as
("entity"{tuple_delimiter}<entity_name>{tuple_delimiter}<entity_type>{tuple_delimiter}<entity_des
cription>{tuple_delimiter}<key_score>)
3. Return output in {language} as a single list of all the entities and relationships identified in
steps 1 and 2. Use **{record_delimiter}** as the list delimiter. 4. When finished, output {completion_delimiter}
######################
-Examples- ######################
{examples}
#############################
-Real Data- ######################
Text: {input_text}
######################
Output:
实体提取提示词
---Role--- You are a helpful assistant tasked with identifying entities in the user's query. ---Goal--- Given the query, list all entities. ---Instructions---
- Output the keywords in JSON format. ######################
-Examples- ######################
{examples}
#############################
-Real Data- ######################
Query: {query}
######################
The `Output` should be human text, not unicode characters. Keep the same language as `Query`. Output:
检索增强生成提示词
---Role--- You are a helpful assistant responding to questions about data in the tables provided. ---Goal--- Generate a response of the target length and format that responds to the user's question, summarizing all information in the input data tables appropriate for the response length and
format, and incorporating any relevant general knowledge.
If you don't know the answer, just say so. Do not make anything up. Do not include information where the supporting evidence for it is not provided. ---Target response length and format---
{response_type}
---Data tables---
{context_data}
Add sections and commentary to the response as appropriate for the length and format. Style the
response in markdown.